
“中文大语言模型应用AI训练营” 第三单元于2025年11月13日如期开讲:项目实战一:语音参数提取,本次课程由科大讯飞研究院研究员邵鹏飞老师授课。
本次课程通过工具讲解与实战演练相结合的方式,邵老师前半程详细演示了语音信号处理中语音参数提取的关键Praat脚本用法,后半程则聚焦Python与VS Code的协同配置,为学员打通从语音标注到相关数据处理的语音信息分析准备流程,助力解决实际研究中的批量数据处理需求。
一、Praat脚本:提取语音分析的核心参数
邵老师结合上节课的示例数据进行教学,重点讲解音素统计、替换及提取共振峰和时长参数等语音数据预处理关键技能。学员们学习了如何通过课程提供的praat脚本,从TextGrid标注文件中提取语料音素列表,摸清标注语料中的音素分布情况。
音素统计技能方面,邵老师通过课程提供的专属脚本,可直接从TextGrid标注文件中提取语料中的所有音素,清晰呈现音素分布及出现频次。
在音素替换环节,邵老师强调了结合表格自动归整的操作技巧:需先在Excel中制作旧音素与新音素的映射表,再导出为制表符分隔的文本文件,避免手动输入导致的格式错乱。
共振峰、时长等关键参数提取脚本可以自动逐条提取每个音段的参数数值,并以文本格式保存结果,方便后续分析使用。
针对前两次课学员普遍存在的路径报错问题,邵老师还特别强调了脚本运行中的路径使用。相对路径(如out15/)无需指定盘符,适用于脚本与文件在同一目录的场景,灵活适配不同存储设备;绝对路径(如 F:\示例数据\1-演示15句\out15)需完整标注磁盘与目录信息,适合跨目录操作。
(直播讲解界面)
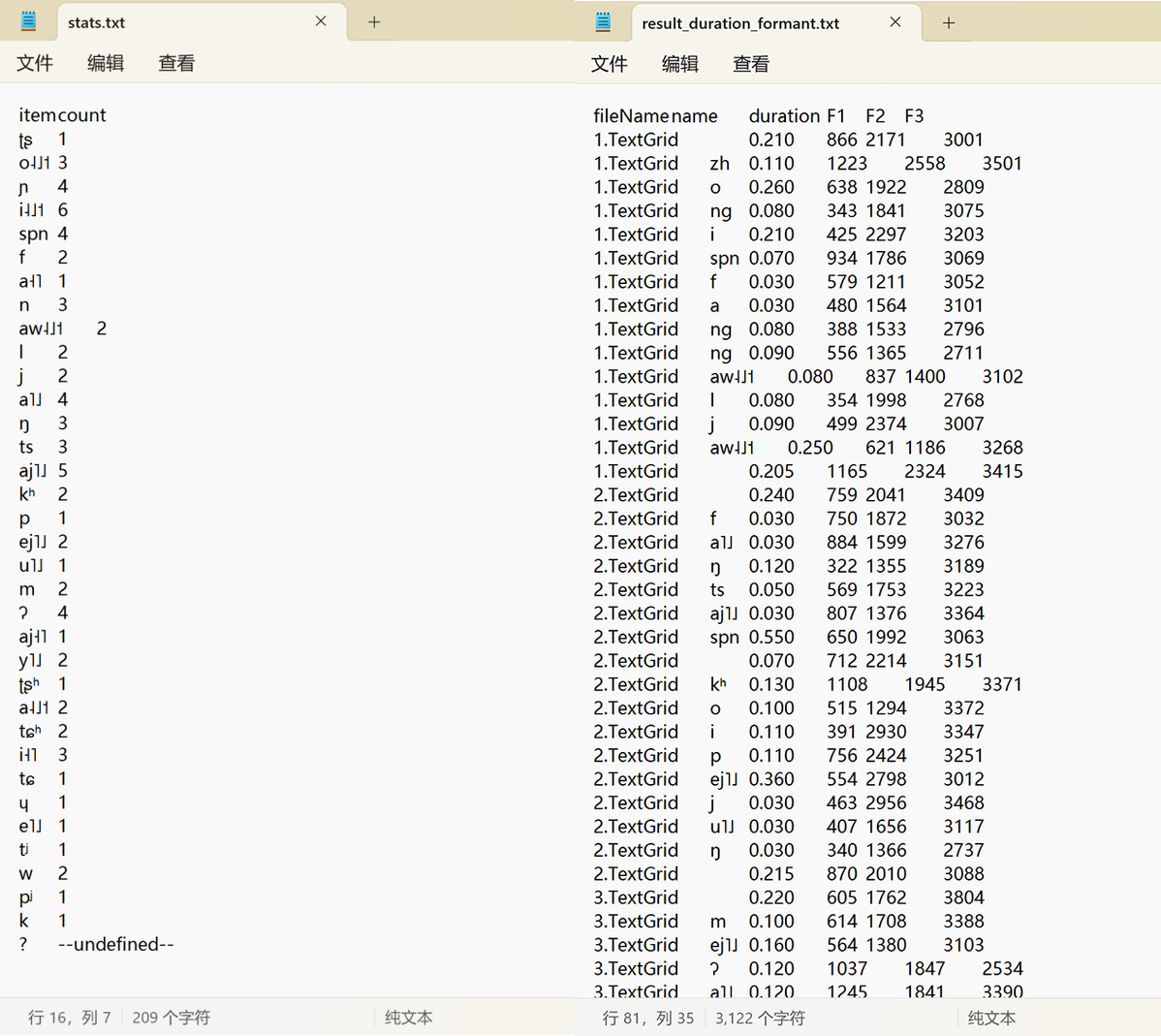
(音素统计与参数提取结果示例)
二、Python+VS Code:高效实现数据自动化处理的环境搭建
课程下半场聚焦Python编程与VS Code环境配置,邵老师帮助学员搭建高效的数据处理工作流。
邵老师首先回顾了上节课讲到的Conda虚拟环境的创建与管理方法。在VS Code配置环节分步指导学员操作,推荐了Audio-Preview、Office Viewer、Rainbow CSV等实用插件,进一步提升数据处理效率。
实战演练环节,学员跟随邵老师完成三大核心任务。一是通过Python脚本批量重命名音频文件并生成同名txt文本;二是利用pandas与openpyxl两个库,将共振峰提取的文本结果快速转为Excel格式,直观呈现参数数据;三是通过Python代码帮助统一音频与文本命名,确保大规模语料处理时的数据一致性。
在实战演练过程中,邵老师对终端操作技巧进行了讲解。主要是在VS Code中通过“Terminal→New Terminal” 可打开命令窗口,输入不同指令可实现虚拟环境的激活与退出、指定Python版本等操作。讲解过程中,邵老师还特别提醒大家熟悉“转义符”的使用;在路径字符串前添加小写“r”(即原始字符串标识),可避免反斜杠“\”被误判而导致解析错误。
(直播讲解界面)
三、课后实操要点
1. 安装VS Code并配置Python插件,在D/E盘创建专属工作目录(避免C盘用户目录权限问题),搭建Conda虚拟环境并安装pandas、openpyxl等必备库。
2. 选用课程提供的语料,完成 Praat 脚本的音素提取、替换及共振峰参数提取练习。
3. 通过Excel整理音频与文本的对应关系,利用Python脚本实现批量重命名与结果导出,验证文件匹配度。
4. 登录课程网站查看本节课核心要点及代码资源,按时完成课后作业。
本次课程的技能不仅适用于语音分析,更可迁移至各类数据处理场景。11月20日19:00将开启《项目实战二:元音分类器》课程,敬请期待!
训练营课程网址:
欢迎持续关注,解锁更多“中文+AI”跨界技能!