
2025年11月20日晚,“中文大语言模型应用AI训练营”迎来第一次系统的大模型操作过程实践课 MFA 声学模型训练。实践演示、指导由科大讯飞研究院研究员邵鹏飞老师担任。实践课程有下面几项主要工作。
4.1 聚焦利用汉语方言材料训练MFA声学模型。
实践、应用落地是我们这次AI训练营的宗旨。针对上一堂课学员在实际操作过程中遇到的具体问题及相关反馈,本次课程对教学内容进行了针对性调整与深化,核心议题聚焦于利用汉语方言材料训练MFA声学模型,并演示如何利用该模型对音频边界进行分段标注。
4.2 高质量的数据准备工作是关键。
在课程上半部分,邵老师首先对MFA的工作原理进行了回顾与阐释。他指出,MFA的运行本质上是一个应用声学模型的过程,模型最终的输出效果与训练样本的质量存在直接且紧密的逻辑关联。基于此,高质量的数据准备工作显得尤为关键。课程明确了训练模型所需的三项核心数据要素:语音音频文件、对应的转写文本以及发音字典。
4.3 虚拟环境的创建与设置流程
在技术环境搭建方面,课程对基础操作进行了系统复习。考虑到学员所使用的操作系统及技术背景存在差异,邵老师详细演示了Conda虚拟环境的创建与设置流程,以及Visual Studio Code开发工具的具体操作方法。演示内容涵盖了如何在Visual Studio Code中正确安装和配置Python运行环境等细节,旨在确保所有学员具备统一且稳定的软件操作基础。
为了直观展示数据处理流程,同时考虑到不同学员自有语料规模与类型的非一致性,本次教学选取了Common Voice开源数据集中的粤语语音材料及其对应的转写文本作为基础素材,并引入了PyCantonese工具包。在实操环节,通过该工具包完成了文本的分词处理以及文本转粤语拼音的操作,完整展示了从原始数据到符合MFA训练要求的语音及文本数据的准备全过程。
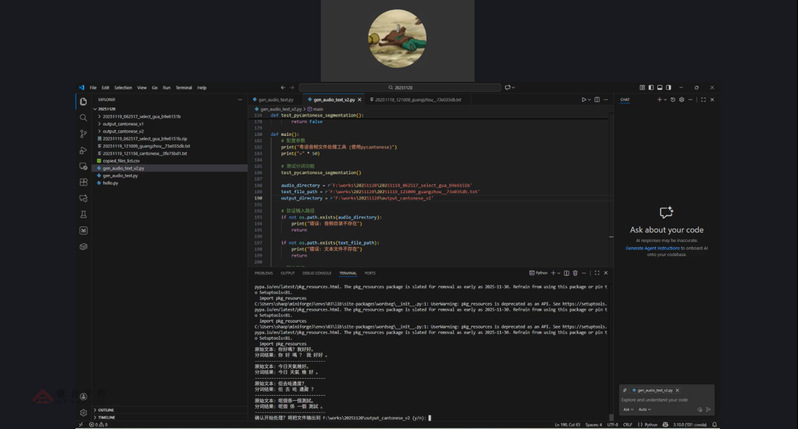
邵老师演示利用pycantonese工具包处理粤语Common Voice数据及分词转拼音的操作界面
4.4 数据准备过程演示
在数据准备过程中,课程引入了当前主流的大语言模型辅助教学。邵老师详细演示了如何利用Deepseek、豆包等大模型工具辅助Python代码的编写。这一环节的重点在于将具体的需求转化为大模型可理解的提示词。演示展示了从初步需求输入,到根据大模型生成的代码结果进行调试、报错分析,再到反向修改和优化提示词的完整迭代过程,最终获得稳定且匹配特定数据处理需求的代码脚本。
4.5 代码脚本的修正与实操应用
课程下半部分重点集中在代码脚本的修正与实操应用。邵老师在讲解并修改由大模型生成的Python脚本的同时,系统梳理了一份关于利用大模型生成Python代码的提示词编写指南。该文档详细阐述了在与大模型交互时的关键要素,特别强调了在代码生成过程中区分“相对路径”与“绝对路径”的重要性,以及向大模型提供具体数据示例(Few-shot prompting)对于提高代码生成准确率的必要性。
随后,经过修正和调试的Python脚本被应用于实际的数据处理流程中,完成了对演示数据的自动化处理。
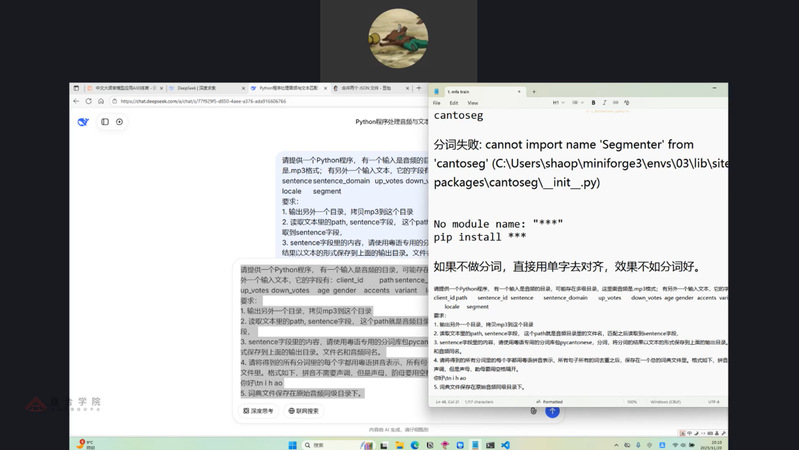
课程中展示的利用大模型生成Python脚本的调试过程及提示词优化文档截图
课程尾声,邵老师对本次教学内容进行了总结。他再次重申了数据质量在模型训练中的决定性作用,指出更多数量、更优质的文本、语音以及精准的词典数据,是获取高性能声学模型及准确标注结果的基础。本次课程通过理论讲解与全流程实操演示相结合的方式,完成了从环境配置、数据清洗到模型训练准备的系统性教学。
4.6 后续课程预告
本次课程的技能不仅适用于语音分析,更可迁移至各类数据处理场景。11月27日19:00将开启《项目实战二:元音分类器》课程,敬请期待!
训练营课程网址:
欢迎持续关注,解锁更多“中文+AI”跨界技能!