
“中文大语言模型应用AI训练营”第五课于2025年11月27日晚开讲,本期课程由科大讯飞研究院研究员邵鹏飞老师主讲,重点围绕基于SVM的元音分类器展开系统教学。课程内容涵盖理论基础与实战操作,内容特别突出实操性。
5.1 从理论到实践:SVM赋能元音分类
邵老师从机器学习的基本算法入手,系统介绍了分类、回归、聚类、生成与序列预测等核心任务,并指出传统机器学习理论是深度学习与神经网络发展的重要基础。
他进一步阐释,分类任务的本质是从已知样本中学习特征规律,从而对新样本进行类别判断。在语音处理中,通过输入元音的共振峰(F1/F2/F3)和时长等声学参数,模型能够自动识别出语音片段对应的具体元音类别。
基于相同的算法逻辑,邵老师进一步举例说明了分类任务的多种应用场景,如方言元音识别、儿童与成人元音区分、异常语音检测(如声带小结患者)以及乐器音色分类等。这些应用本质上均遵循“特征—类别”的分类逻辑。
邵老师指出,SVM之所以适用于元音分类,源于其小样本泛化能力强、模型结构清晰、解释性高等特点,非常适合于教学演示与实际语音建模场景。相比之下,逻辑回归、决策树等模型在类似任务中存在一定局限性。
除元音分类外,邵老师也举例说明了SVM在语音研究中的多种延伸应用,如声调分类、语音端点检测、说话人识别、语音情感识别及语音质量评估等。
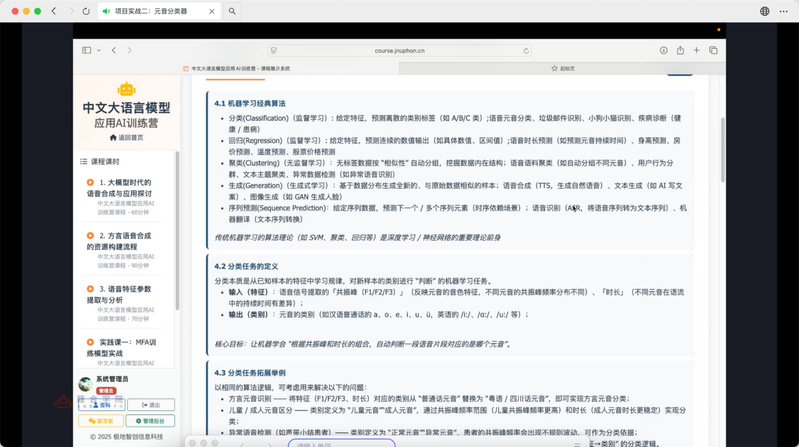
邵老师理论讲解截屏
5.2实战演练:方言数据训练SVM模型
实践与应用落地是本次AI训练营的核心目标。在理论讲解之后,邵老师带领学员进入实战环节,演示如何利用汉语方言材料训练SVM声学模型,并完成具体元音的自动分类。
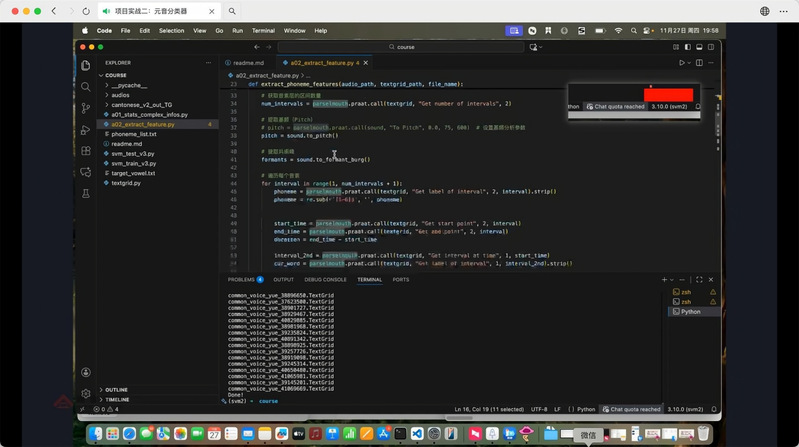
邵老师实战演练截屏
邵老师以a、ang、au等元音为例进行实际操作,学员们跟随演示同步练习。他特别强调,高质量的数据准备是整个流程的关键环节,完善的数据预处理将为后续建模奠定坚实基础。
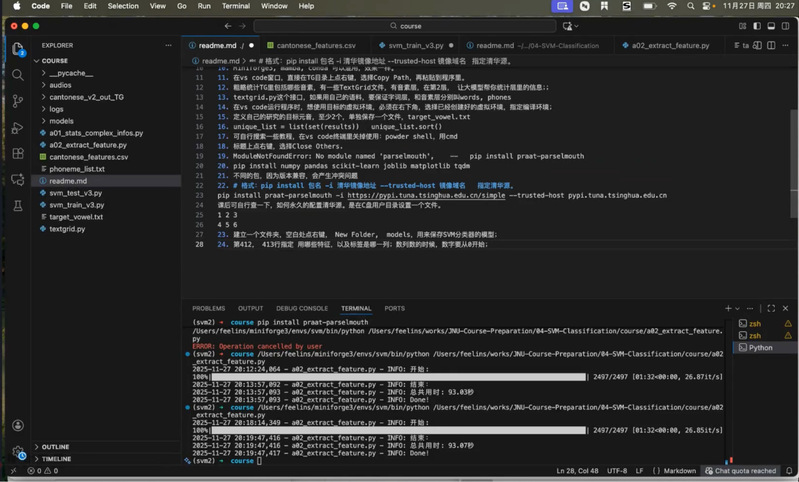
邵老师详细讲解操作步骤
课程尾声,邵老师对本次授课内容进行了总结,再次强调了数据准备阶段的重要性。整节课通过“理论+实操”相结合的方式,系统性地完成了从分类器选择、环境配置、数据准备到模型训练的全流程教学,为学员构建了完整的语音分类实践基础。
5.3后续课程预告
本课所授技能不仅适用于元音分析,还可迁移至多种数据处理场景。12月4日19:00,训练营将推出《项目实战三:声调分类模型》课程,敬请期待!
训练营课程网址:
欢迎持续关注,解锁更多“中文+AI”跨界技能!