
2025年12月11日晚,“中文大语言模型应用AI训练营”第六课顺利开讲。本次课程由科大讯飞研究院研究员邵鹏飞老师主讲,聚焦使用LSTM(长短期记忆网络)的声调分类模型训练及推理,带领学员从模型选型逻辑出发,一步步拆解数据准备、环境搭建、模型训练与推理验证的完整链路。
6.1 声调分类的模型选择
对声调进行分类识别是本次课程的主题。
邵老师指出汉语等语言声调“平、升、降、折”的变化,本质是语音信号的时序特征表现。但在传统语音信号分析模型中难以捕捉这种随时间变化的依赖关系,因此早期的语音特征分类模型对于声调的分析效果较差。而LSTM是“有记忆的模型”,该模型不仅能记住前面的基频数据,还能结合后续变化判断整体趋势,突出数据的时序形状变化。因此相比之下,SVM更适合共振峰分类这类静态特征任务,LSTM则是专门为连续数据量身定做的模型。邵老师还补充到,类似的时序模型还有RNN等,但LSTM在避免梯度消失、长时记忆保留上更具优势,是当前业界的优选方案。
6.2 声调分类训练的数据准备
考虑到学员前期的学习基础和操作习惯,邵老师详细演示了使用Praat脚本提取数据的完整流程。首先,选用带有声调标注层的粤语材料作为数据源,重点说明了提取基频(Pitch)和时长(Duration)两大核心特征的方法。同时特别提醒学员注意不同操作系统下目录路径的规范书写差异。例如Windows系统需用反斜杠“\”,Mac系统需用斜杠“/”,且路径末尾必须保留对应符号,否则会导致文件读取失败。最后,他还强调要通过过滤辅音数据、仅保留纯净元音段落的方式完成数据清洗,避免因数据混杂影响训练效果。
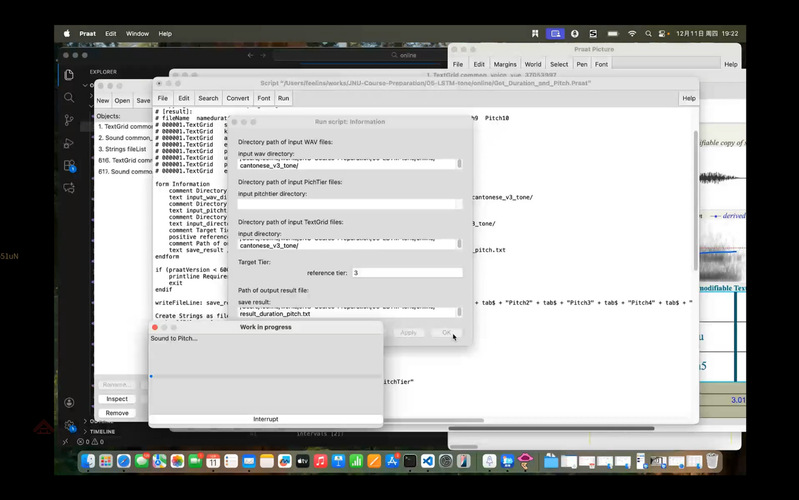
邵老师使用Praat脚本提取数据的操作界面
6.3 粤语声调分类实践
在该部分,课程延续训练营实战导向,邵老师提前为学员准备了训练所需的序列数据,以便同步教学进程。训练流程与上节课SVM元音分类器一脉相承,核心步骤如下:
(1) 环境搭建:复用或新建Python虚拟环境,安装numpy、pandas、matplotlib、torch等核心包,网络较慢时可通过清华源(https://pypi.tuna.tsinghua.edu.cn/simple)加速下载,尤其针对torch等大型库;
(2) 脚本配置:修改train_LSTM.py中的输入路径,匹配本地数据存储位置;重点提醒学员根据数据格式调整分隔符参数——若数据用逗号分隔则保留默认配置,若为 Tab分隔需手动修改加载函数;
(3) 特征灵活选择:除基础的10个基频点和时长外,学员可根据需求添加基频均值、方差、最值等统计特征,进一步提升模型表现力。
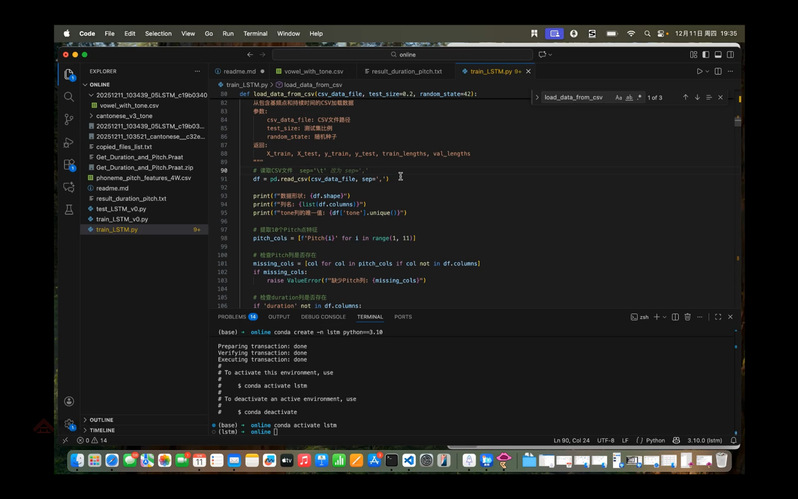
根据数据分隔符修改脚本的实操界面
训练过程中,学员们发现初步训练结果并不理想,粤语声调分类的准确率仅为20%左右。邵老师指出了造成该问题的核心原因:一是粤语声调类别多,分类任务复杂;二是当前可用的标注样本数量不足;三是数据来源于自动标注,未经过人工校对,数据精确度有限。这一结果印证了数据质量对模型性能的重要影响。
6.4汉语普通话声调分类实践
为了让学员直观感受数据质量对模型的影响,邵老师切换至标贝科技中文普通话开源数据集进行演示。该数据集包含1万句高质量录音,可提取约12万条元音段落,数据量充足且标注规范,所训练的模型准确率可达80%以上。训练曲线呈现出清晰的“损失下降、准确率上升”趋势,生成的混淆矩阵能直观反映各类声调的识别效果。
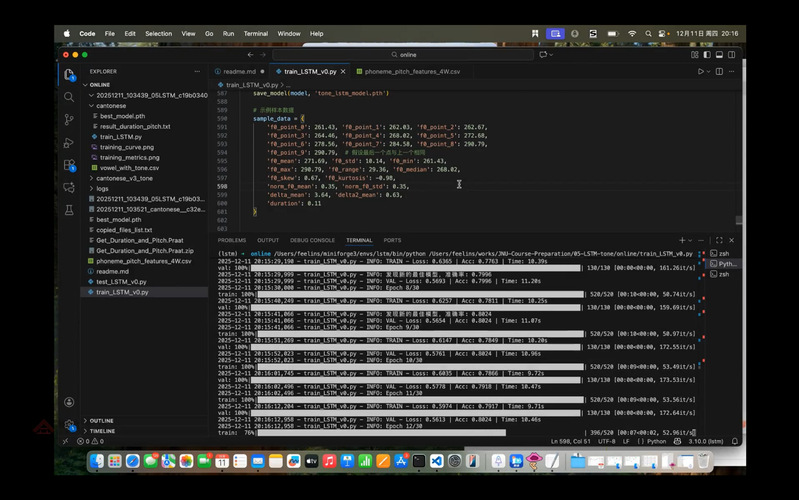
模型训练过程界面
6.5 闭环检验与模型推理预测
最后,邵老师带领学员完成推理预测闭环,实现“训练-验证-应用”的完整落地。邵老师使用训练过程中保存的best_modelNaNh,对预设样本进行推理,通过10个基频点及时长特征精准预测声调类别,并输出各类别的预测置信度,并且鼓励学员录制个人普通话元音数据,提取关键特征后导入模型进行预测,或是复制脚本中393-407行的测试数据,实现批量预测,检验模型泛化能力。
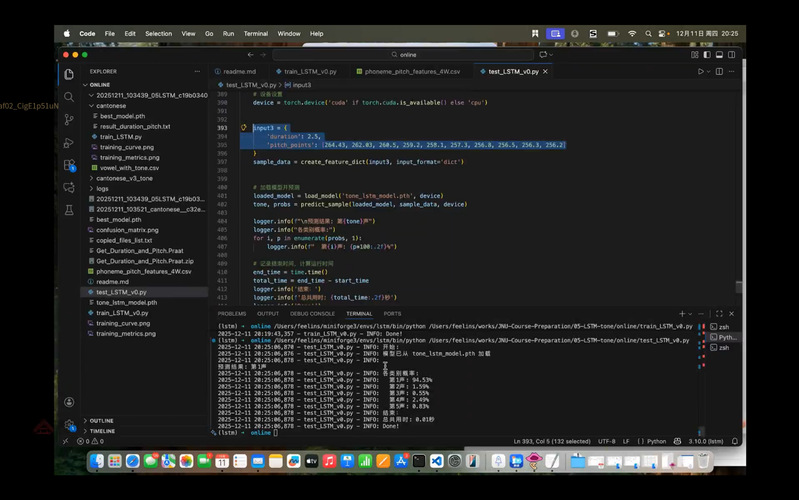
模型预测操作界面
6.6 后续课程预告
本次课程旨在帮助学员理解LSTM模型的训练与预测逻辑,学会声调模型的训练步骤,以便结合个人需求进行进阶操作。12月18日19:00将开启《项目实战四:IPA识别模型》课程,学习wav2vec2.0微调,在工作站启动训练,对比微调前后准确率。敬请期待!
训练营课程网址:
欢迎持续关注,解锁更多“中文+AI”跨界技能!