
2025年12月18日晚,“中文大语言模型应用AI训练营”迎来第七次课程,由科大讯飞研究院研究员邵鹏飞老师主讲,聚焦于前沿的自监督学习模型Wav2Vec及其在语音处理领域的应用。
7.1 核心技术解析:Wav2Vec系列模型的思想与优势
课程首先深入剖析了Wav2Vec系列模型的核心思想。邵老师指出,Wav2Vec的突破在于让模型能从未经标注的原始音频中,通过自监督学习的方式,自主学习高质量且通用的语音特征表示。这种学习到的特征表示,相比于传统的手工设计声学特征(如MFCC),包含更高层次的语音和语言信息,表现得更为稳健。他强调,Wav2Vec之所以在语音处理领域如此重要,主要有以下几点原因:一、打破数据标注瓶颈,模型能够有效利用互联网上不计其数的无标签语音数据进行学习,极大地降低了对昂贵人工标注的依赖;二、推动低资源语言技术发展,通过在多语言数据上进行预训练,Wav2Vec能够轻松适配到特定语言,显著提升了低资源语言的语音识别性能;三、构建统一的语音表示框架,其学习到的通用表示不仅限于语音识别,还能广泛应用于语音合成、情感识别、声纹确认及语音翻译等多种下游任务。
7.2 模型微调与应用:从预训练到任务适配
在对核心概念进行讲解后,课程的重点转移到了模型的微调阶段。邵老师解释,经过大规模数据预训练的Wav2Vec模型,如同一个“语音理解专家”,需要通过微调来适配具体的下游任务。
以自动语音识别(ASR)为例,典型的微调操作是在预训练好的Wav2Vec 2.0模型之上,添加一个随机初始化的线性层作为分类头,并利用带标签的音频数据,通过连接主义时间分类(CTC)损失函数进行联合优化。得益于主干网络强大的语音表示能力,仅需少量标注数据,微调后的模型便能达到甚至超越传统方法使用海量数据训练的效果,充分展现了其在“少样本学习”或“高效微调”方面的巨大潜力。
7.3 课堂实操演示:环境搭建与对比实验
为了让学员对理论有更直观的认识,邵老师精心设计了课堂演示环节。整个流程从数据和环境的准备工作开始。
(1)数据准备:选取了Common Voice开源数据集中的闽南语材料作为本次演示的数据。
(2)虚拟环境搭建:详细演示了如何在Conda虚拟环境中安装Wav2Vec及本次实验的核心工具——开源的音素对齐工具包Charsiu。
在对比实验环节,邵老师展示了不同模型和方法在处理闽南语材料时的效果差异:
(1)MFA与Charsiu效果对比:首先,将之前课程中使用的MFA(Montreal Forced Aligner)对齐效果与基于Wav2Vec微调的Charsiu工具包进行对比。结果显示,Charsiu的对齐效果明显优于MFA。

使用基于wav2vec微调的Charsiu工具包(上)和使用MFA(下)的效果对比
(2)Charsiu有/无文本标注对比:接着,比较了Charsiu在提供转写文本和不提供转写文本两种模式下的标注结果。实验发现,无文本模式下的效果虽略逊一筹,但其自动化处理能力依然能大幅提升工作效率。
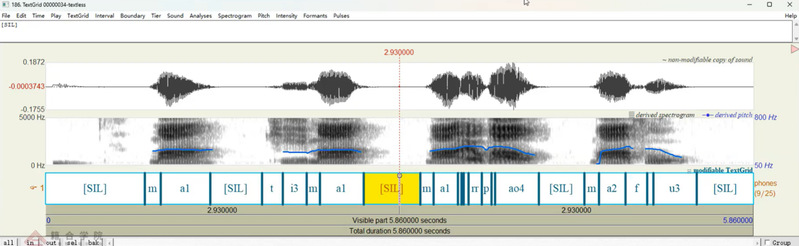
相同语音应用Charsiu的无文本标注的效果对比
(3)跨语言模型性能比较:课程还引入了主要基于英语语料训练的vitouphy/wav2vec2-xls-r-300m-timit-phoneme模型与Charsiu进行比较。值得注意的是,尽管训练语料存在巨大差异,vitouphy模型在处理闽南语数据时依然表现出不错的效果。
用闽南语的语音样本“相拄头”作为示例
7.4 总结与启示
课程尾声,邵老师对本次教学内容进行了总结。他指出,对比实验的结果有力地证明了以Wav2Vec 为代表的自监督学习方式,能够直接从原始音频中提取深度表征,摆脱了对人工标注的绝对依赖;尽管人工干预并非必要前提,但通过后期微调,可以使模型更精准地契合特定应用场景。 这种特性有效降低了不同语言之间在声学特征和音素识别上的壁垒,为跨语言、低资源的语音研究与应用提供了全新的可能性。本次课程通过理论与实践的紧密结合,不仅让学员掌握了Wav2Vec模型的核心原理与微调方法,更通过Charsiu工具包的实操演示,直观展示了前沿AI技术在解决实际问题中的强大能力。
7.5 后续课程预告
本次课程的技能不仅适用于语音分析,更可迁移至各类数据处理场景。12月25日19:00将开启《IPA识别模型及训练》课程的巩固与答疑,敬请期待!
训练营课程网址:
欢迎持续关注,解锁更多“中文+AI”跨界技能!