
2025年12月25日晚,“中文大语言模型应用AI训练营”迎来第八次课程,由科大讯飞研究院研究员邵鹏飞老师主讲。本节课延续第七课Wav2Vec 2.0模型的核心理论,是《IPA识别模型及训练》的实操进阶课程,聚焦IPA识别模型的全流程训练实践,通过语料预处理、模型微调、推理测试等实操环节,帮助学员掌握低资源语言语音识别的关键技术,破解训练过程中的常见难题。
8.1 课前准备:语料优化与环境搭建
课程伊始,邵老师明确了本次实操的核心基础——数据与环境的双重准备。数据准备方面,训练模型需准备“音频-文本”对。邵老师选用Common Voice开源平台的闽南语语料作为材料处理样本,为匹配Wav2Vec 2.0底座模型的输入要求,所有音频需预先处理为16KHz采样率。
环境配置环节,邵老师建议学员使用上节课建好的wav2vec环境,若出现依赖冲突,可重建全新环境,按脚本运行报错提示逐项安装缺失组件。此外,学员需提前下载两类关键资源:
一是Facebook发布的底座模型(模型下载链接已上传至本课程网站);
二是课程配套的代码包,包括音频转采样率、JSON配置生成、训练数据打包、训练和推理五个Python脚本。
8.2核心实操:五步训练流程解析
本节课的核心是完整落地模型训练的五步流程,邵老师针对每一步的关键要点和可能出现问题的处理方式进行了详细演示:
1. 音频转采样率:因Wav2Vec 2.0底座模型的输入要求,非16KHz采样率音频需通过脚本统一转换,确保与底座模型兼容。
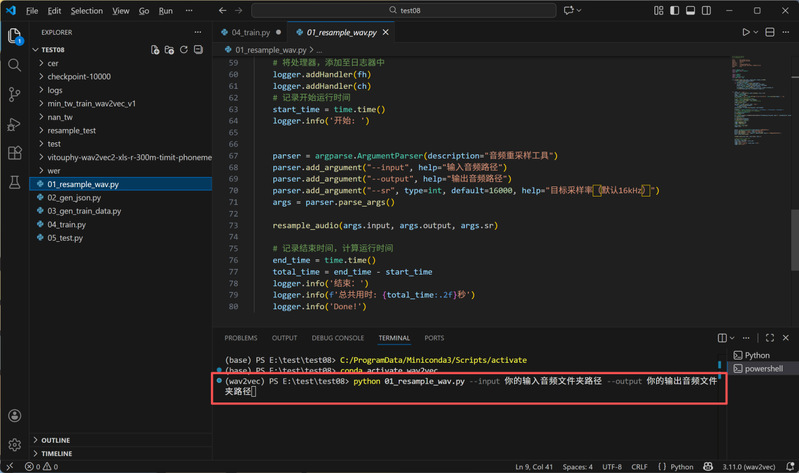
音频转采样率的脚本运行步骤
2. 生成JSON配置文件:该步骤的核心作用是梳理音频与文本的对应关系,明确文件绝对路径,为后续数据加载提供规范索引。运行脚本后会自动统计训练集、验证集、测试集的时长分布,生成的JSON文件将明确每条样本的音频与文本绝对路径,为后续数据加载提供规范索引。学员使用时需注意修改脚本第67-69行的路径参数:第67行为项目基础目录(需手动创建),第68行为文本文件存储目录,第69行为16KHz音频文件存储目录。
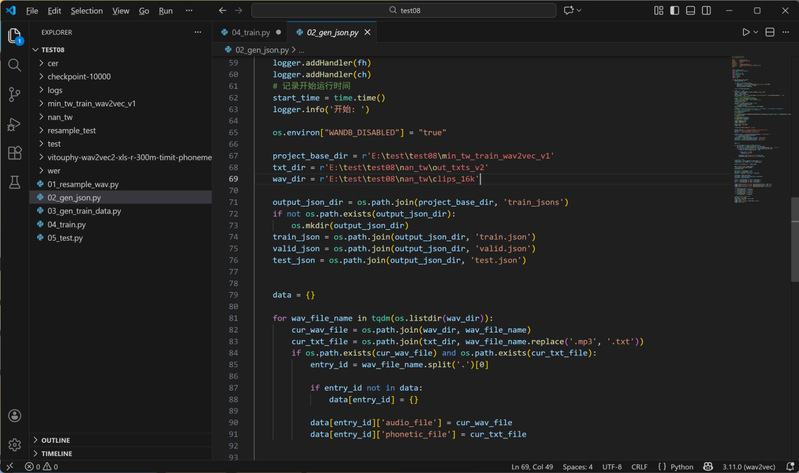
JSON配置文件脚本的路径参数修改界面
3. 打包训练数据:通过脚本将音频采样点与文本标记转换为模型可识别的格式,同时生成vocab.json词汇表。此步骤需重点处理两类问题:一是过滤语料中的特殊符号,二是统一声调表示(如将声调统一用数字表示),确保数据纯净性。
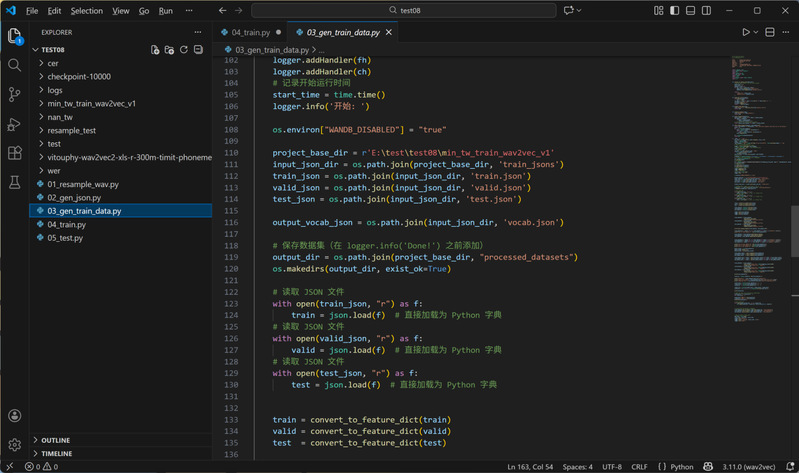
训练数据打包脚本的核心参数修改界面
4. 执行训练脚本:这是本次IPA模型训练的核心环节。基于Wav2Vec 2.0底座模型进行微调,通过CTC损失函数优化,支持断点续训(指定检查点路径即可恢复训练),并默认保留验证集loss最优的3个模型。在此环节中,邵老师特别提示:训练时长与硬件配置强相关;训练过程需重点关注词错误率(WER)和字符错误率(CER),模型初始错误率通常为100%,约3000个epoch后开始显著下降,1万epoch时CER可降至18%,表明模型已稳定收敛。普通电脑若想快速观察训练趋势,可将脚本中的评估步数从100步改为10步,每10步输出一次loss值。
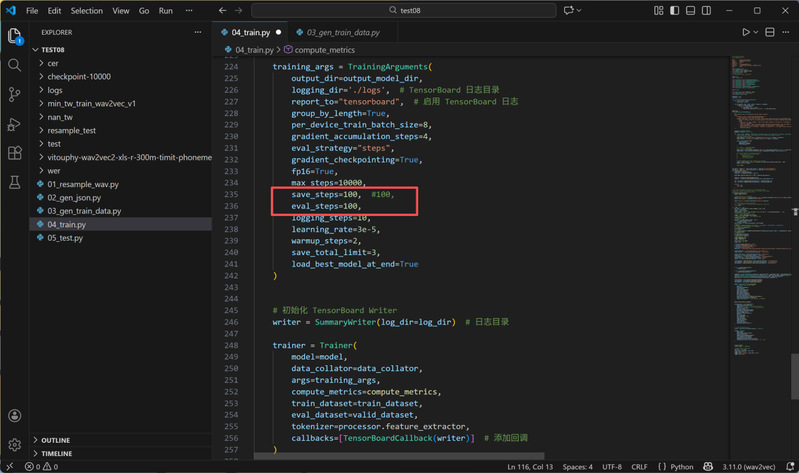
训练脚本评估步数修改界面
5. 推理测试:加载训练完成的模型及对应的vocab.json文件,输入16KHz音频即可生成识别结果。课程中邵老师以饶平闽语句子“上小学、中学都学普通话”为例,进行演示,模型成功识别出对应拼音序列。该环节测试时有三个注意事项:一是预测结果中的“pad”标记无实际意义,可替换为空格;二是脚本中“device = 0”表示使用GPU加速推理(无GPU可改为“device = -1”);三是声调识别准确率相对较低,核心原因是底座模型缺乏足够的中文声调数据支撑。
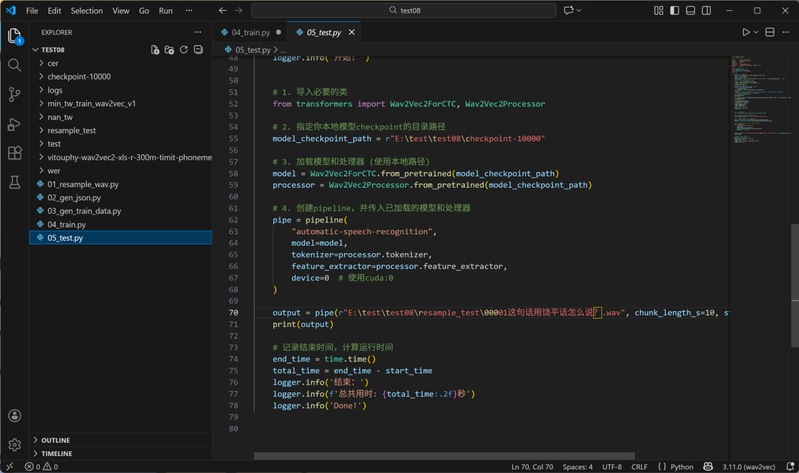
推理脚本核心代码修改界面
8.3 课程小结与拓展
本节课通过“理论+实操+问题拆解”的模式,让学员清晰全面地了解并掌握IPA识别模型的训练过程。除了课堂学习,邵老师建议学有余力的学员可在课后进行拓展实践:下载TIMIT英语语料库进行对比研究,分析带词边界和音素标注的语料对训练效果的影响;优化声调映射表,提升闽南语声调识别准确率;尝试将训练流程迁移至其他低资源方言或小语种等相关实践,提高对模型架构的理解。
8.4 后续课程预告
训练营将持续通过课程平台提供技术支持,解答学员训练过程中的疑问。下节课将开启《方言平行语料翻译》课程,教你如何使用LLM提示工程/LoRA微调,构建方言平行语料库。敬请期待!
训练营课程网址:
欢迎持续关注,解锁更多“中文+AI”跨界技能!