
2026年1月8日,继第八课深入探索IPA语音识别模型后,“中文大语言模型应用AI训练营”第九课正式开启了方言平行语料翻译的进阶篇章。邵鹏飞老师带领学员们从语音领域跨入文本生成领域,基于NLLB多语言底座模型,利用LoRA(Low-Rank Adaptation)技术,手把手演示了如何训练一个专属的“方言-普通话”翻译模型。
9.1 理论先行:打造“会学语言的智能翻译官”。
课程伊始,邵老师首先用通俗易懂的比喻阐述了翻译模型的本质。不同于死记硬背的字典,翻译模型更像是一个“会学语言的智能翻译官”。它不依赖机械的词对词替换,而是通过学习语言规律,实现举一反三。例如,教会模型“侬好=你好”、“今朝=今天”,它就能自动推导出“侬好,今朝天气老好个”对应的普通话翻译。
邵老师强调,本次训练采用NLLB(No Language Left Behind)作为预训练底座。这相当于雇佣了一位已经精通200种语言的“资深翻译”,我们只需通过平行文本(即粤语-普通话的对照句子)对其进行针对性的“方言岗前培训”,就能以极低的成本获得高质量的方言翻译模型。
9.2 核心实操:低资源环境下的模型微调
在实操环节,邵老师考虑到学员们不同的网络环境与硬件条件,演示了本地化加载资源与低显存优化的训练方案。
(1)从云端到本地——环境与数据准备。
为了确保训练的稳定性,邵老师演示了如何跳过网络连接,直接加载本地下载好的Hugging Face数据集与模型文件。代码中特别展示了如何设置 PyTorch 的 MPS 环境变量,并通过local_datasets读取本地粤语-普通话(Cantonese-Mandarin)数据集的过程;下方的终端窗口则展示了 Conda 虚拟环境的安装与激活过程(conda activate translation),标志着模型训练前的环境准备工作完成。
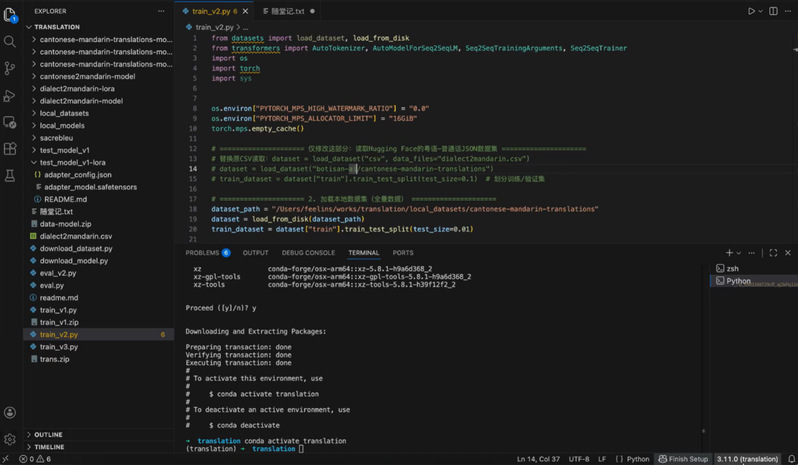
开发环境配置与数据加载
(2)构建标准化“教材”——数据预处理。
模型听不懂人类语言,只认得数字。邵老师详细讲解了预处理函数preprocess_function 的逻辑:首先给所有输入文本加上前缀指令 “translate dialect to mandarin:” ,明确任务目标;随后通过分词器(Tokenizer)将方言文本和普通话标签转换为模型可读的Token ID,并统一截断或填充至固定长度(如128或512),确保“教材”格式整齐划一。
(3)LoRA配置与参数优化——给大模型“减负”。
这是本节课的技术高光时刻。面对拥有6亿参数的NLLB模型,全量微调对显存要求极高。邵老师引入了LoRA技术,仅针对Transformer架构中的q_proj和v_proj层进行微调,将可训练参数压缩至总参数量的0.1%左右。
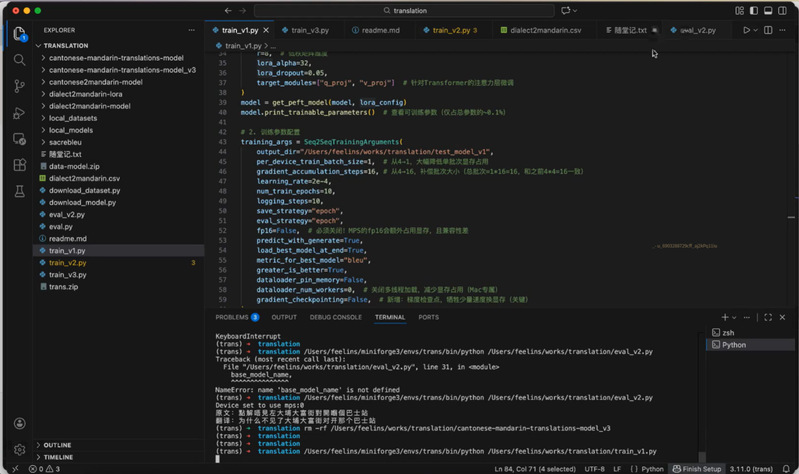
配置微调参数与调试报错对策讲解
(4)训练演示与BLEU评估。
代码运行后,控制台开始实时输出训练日志。邵老师向同学们展示了Loss(损失值)如何随着步数增加而一步步趋近于零,这象征着模型正在不断修正自己的错误。
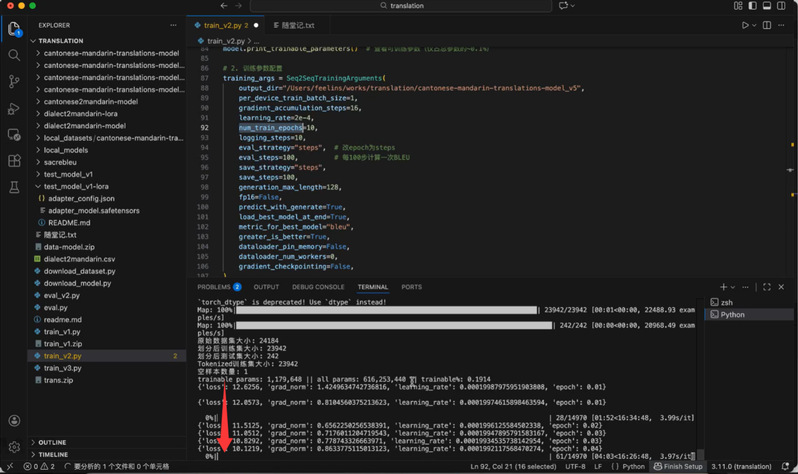
监控训练进度与Loss变化
为了验证模型效果,邵老师介绍了BLEU分数这一评估指标。他指出,由于演示用的数据量较少,BLEU分数可能不会非常理想,但这恰恰展示了真实训练中的常态——数据量与质量直接决定翻译的上限。

机器翻译评估指标“BLEU分数”详解
此外,邵老师还提示学员需准备一个包含dialect和mandarin两列的CSV文件作为独立测试集,用于课后验证。
(5)推理测试:见证“方言插件”生效。
模型训练完毕并保存后,邵老师演示了推理(Inference)过程。加载微调后的LoRA权重,输入一句粤语:“我依家喺上水衞和街,附近有停車場泊車嗎”,模型成功将其翻译为普通话。这一过程直观展示了模型如何将学到的方言规律应用到新句子中,且进一步地展示了模型训练步数的差异所生成的翻译差异。
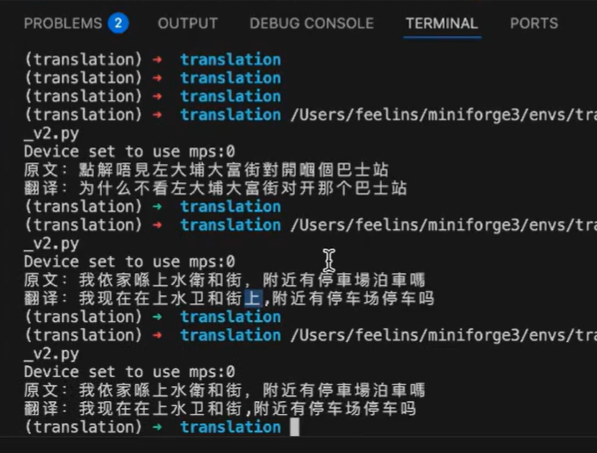
粤语转普通话模型推理实测演示
9.3 课程小结与展望
本节课通过“理论拆解+代码实操”的方式,打通了从数据加载、LoRA微调到模型推理的全流程。邵老师特别强调,掌握这套流程后,学员们不仅可以做粤语翻译,还可以通过更换数据集,训练客家话、吴语甚至文言文的翻译模型。
9.4 后续课程预告
随着翻译模型的跑通,我们的“方言AI工具箱”已初具规模。下节课,我们将进一步探讨如何将训练好的模型进行部署与应用,或者深入探索更多大语言模型的高级微调技巧。
训练营课程网址:
https://app7iixgnpj3504.pc.xiaoe-tech.com/p/t_pc/course_pc_detail/camp_pro/course_34RqxxLAHT12KD5bSm1NR7C5b5v
欢迎持续关注,解锁更多“中文+AI”硬核技能!