
2026年1月15日,中文大语言模型应用AI训练营第十课——“方言口音识别”实战课正式开讲。邵鹏飞老师以“理论拆解+代码实操”为核心,深度聚焦wav2vec模型在方言口音识别中的应用,从技术原理到项目落地全流程拆解,助力学员了解方言识别技术从模型原理到工程实践的全貌。
10.1 理论筑基:解析wav2vec模型的技术优势与应用逻辑
课程开篇,邵老师首先围绕wav2vec模型展开系统讲解,为实操环节筑牢理论基础。他指出,wav2vec模型通过自监督学习提炼的通用语音特征,能够精准捕捉音素、音调、韵律等细微声学差异,而这些差异正是区分不同方言口音的关键所在。相较于传统模型,wav2vec的特征表示更具鲁棒性,且蕴含高层次语言信息,使其成为方言口音识别任务的理想基础模型。
邵老师对技术核心做了深入浅出的讲解:方言口音识别本质是分类任务,在预训练wav2vec模型基础上进行特征微调,即可实现针对性识别。他还详细阐述了该模型的核心优势——有效解决低资源方言的数据标注难题、精准捕捉方言特有的细微声学特征、增强复杂场景下的识别鲁棒性、支持统一框架下的多语种扩展等,通过讲解和实操,学员就可以清晰地理解技术选型的底层逻辑。
在课程讲授中,邵老师还梳理了模型微调的关键步骤,希望帮助学员建立“理论-实操”的衔接认知。
10.2实操攻坚:四步拆解方言口音识别全流程
在理论讲解的基础上,课程进入核心实操环节。邵老师结合具体案例,分步骤演示了从数据准备、模型训练、推理的完整链路,并对关键步骤与常见问题进行了重点提示。
(1)数据预处理与环境配置
邵老师强调,数据适配是模型训练的前提。由于wav2vec底座模型对输入音频有明确要求,所有非16KHz采样率的音频需通过脚本统一转换,确保与底座模型兼容,相关脚本运行步骤已在前期课程中详细讲解。同时,本次课程的虚拟环境与此前IPA识别课程保持一致,邵老师提醒学员复用前期课程已配置好的Python虚拟环境,为后续操作奠定基础。
邵老师实操演示准备核心数据操作步骤
(2)生成标准化数据集
方言口音识别JSON压缩包数据集规范构建完成
数据集构建阶段,通过运行脚本将处理好的音频数据打包生成特定的JSON格式压缩包,作为后续训练的直接输入。邵老师特别提醒实操关键:路径设置需避免使用空格,可采用横杠等符号替代,且输入与输出路径不可重名,需根据实际项目情况灵活修改,确保数据集生成的准确性与可用性,以防运行错误。在老师的指导下,学员逐步完成数据集的规范构建,为模型训练做好数据支撑。
(3)模型训练与参数调试
在训练阶段,邵老师提醒学员使用第6课讲解的wav2vec底座大模型3亿参数版本,需准确修改底座模型路径,并与第二步生成的hf数据压缩包路径保持一致。针对多语种方言识别需求,他强调需根据实际语种数量调整训练设置,确保前后参数统一。考虑到不同学员的网络环境与硬件条件存在差异,可能出现训练缓慢或报错问题,他现场演示了如何通过解读错误日志、调整核心代码进行排查,并建议学员可借助大模型辅助分析代码问题,以适应不同的软硬件环境。
邵老师细致拆解模型训练核心流程
(4)模型推理与效果验证
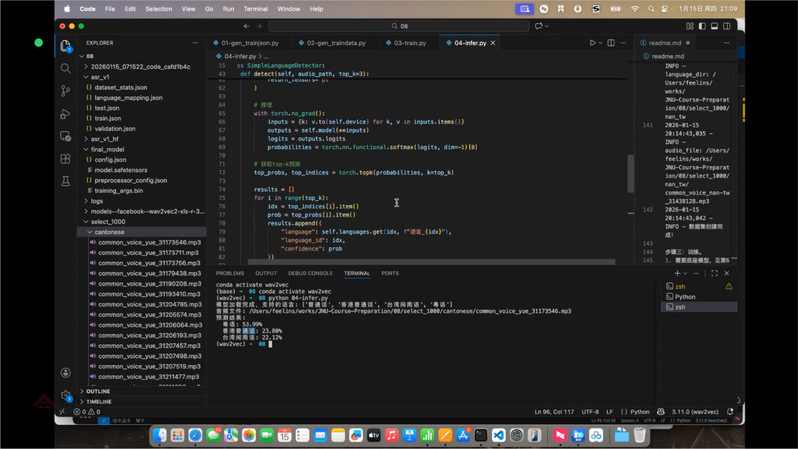
方言口音识别推理实测演示
模型训练完成并保存后,邵老师现场演示推理测试流程:只需准确设置已保存模型的路径与待推理音频文件,运行相关程序即可快速获取预测结果。他鼓励学员课后拓展实践,通过增加训练与测试数据量,进一步提升模型识别精度,深化对技术应用的理解。
10.3 课程总结与展望
课程尾声,邵老师对本次实战内容进行系统总结:本节课通过完整的“理论拆解+代码实操”流程,初步尝试完成了不同方言识别-分类-相似性判断,让学生对方言口音识别有了感性的认识,科研很好地帮助学员掌握方言口音识别分类任务的核心逻辑与操作方法,学员可在此基础上进一步探索多类型方言口音的识别与分类,拓展技术应用边界。
10.4 后续课程预告
训练营将持续提供线上技术支持与答疑。下一课将继续聚焦方言口音数据处理与识别模型的深度应用,带来更多精细化讲解与实操示范,敬请期待!
训练营课程网址:
https://app7iixgnpj3504.pc.xiaoe-tech.com/p/t_pc/course_pc_detail/camp_pro/course_34RqxxLAHT12KD5bSm1NR7C5b5v
欢迎持续关注,解锁更多“中文+AI”硬核技能!