
2026年1月22日,“中文大语言模型应用AI训练营”迎来了方言虚拟人框架搭建学习课程。本节课聚焦训练营核心目标——方言语音合成及其延伸应用,邵鹏飞老师通过GPT-SoVITS框架的全流程实践操作,带领学员完成“语料准备→模型微调→语音合成”的关键环节,为后续虚拟人联动筑牢基础。
11.1核心逻辑:GPT-SoVITS——方言合成的“双引擎”
课程伊始,邵老师讲解和搭建框架GPT-SoVITS,并将该框架拆解为两大核心模块进行讲解,清晰阐释了方言合成的核心原理。
1. SoVITS模块:精准拆解方言发音
该模块如同专业语音老师,能解析声母、韵母、声调及停顿规则,但默认基于普通话拼音体系训练。若直接输入方言拼音(如闽南语拼音“sûn-tsîng”),模型会因无法识别鼻化韵、舌叶音等特殊发音,生成“塑料方言”,因此必须通过方言标注语料进行微调。
2. GPT模块:复刻说话韵律情感
该模块负责捕捉说话人的语气起伏、节奏停顿,让合成语音更具真实感。但它高度依赖SoVITS模块的准确输入,若前期发音标注错误,再生动的情感模拟也会失去意义。
在掌握基础操作的同时,课程还提及CoquiTTS、F5-TTS、Index-TTS等其他主流合成框架,供学员课后拓展学习。
11.2 课前准备:环境搭建与资源下载
要让AI顺利说“方言”,需先完成环境与资源的双重准备。在本节课上,邵老师提供了详尽的实践环境操作指南。
1. 核心资源包获取
课程提供完整项目资源,包括GPT-SoVITS框架代码、预训练模型、合成用语料(以佘诗曼粤语访谈音频为示范)及虚拟环境配置文件。所有资源可通过链接(https://www.yuque.com/baicaigongchang1145haoyuangong/ib3g1e/dkxgpiy9zb96hob4)下载。
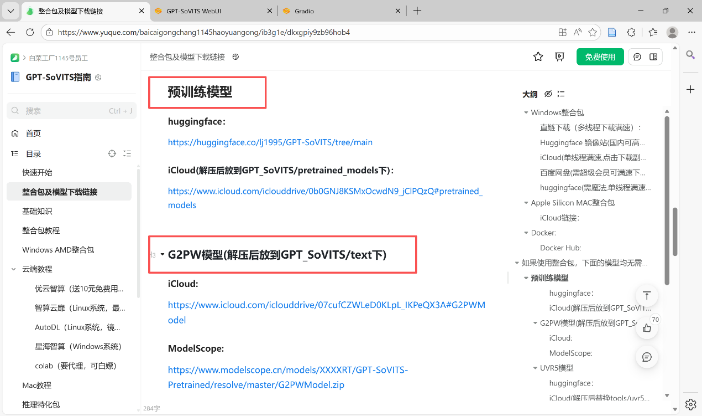
方法一:下载4个模型并进行文件部署
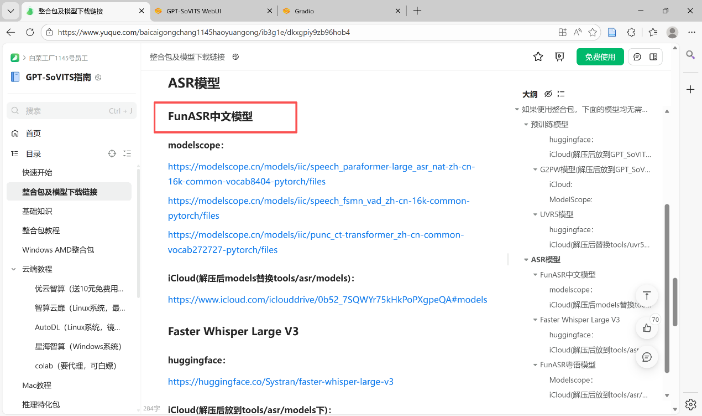
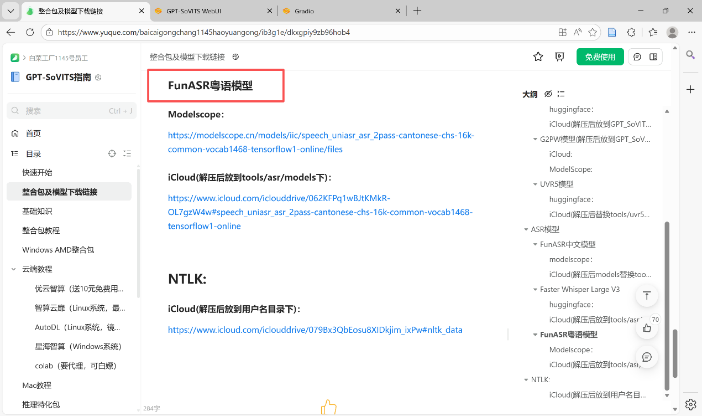
下载预训练模型、G2PW模型、FunASR中文模型及FunASR粤语模型,并需按指定目录放置:将pretrained_models解压至GPT_SoVITS/pretrained_models目录,G2PW模型放入GPT_SoVITS/text目录,FunASR 中文及粤语模型拷贝至tools/asr/models目录,确保程序正常调用。
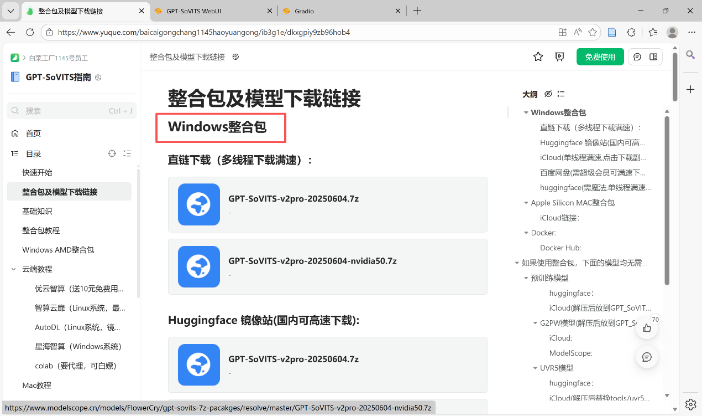
方法二:直接下载整合包
直接下载整合包,其中已包括完成部署的模型及相关代码。
整合包及模型下载链接汇总界面
2. 虚拟环境配置
在实验环境配置过程中,建议创建独立的Python 3.10虚拟环境(conda create -n gpt python==3.10),通过pip install -r 20260121_115140_requiremen_5e0c2f7d.txt一键安装(Python环境文件已包含在课程资源包中),避免依赖版本冲突。
3. 启动GPT-SoVITS WebUI可视化界面
Windows用户可直接双击go-webui.bat启动cmd界面,稍作等待即可打开GPT-SoVITS的可视化界面;Mac和Linux用户则需通过终端运行相应指令(python webui.py zh_CN)。
GPT-SoVITS WebUI可视化界面
11.3 核心实操:从语料处理到模型微调
本节课的核心是完成方言语音合成的全流程训练,以粤语合成为例,关键步骤如下:
1. 语料预处理:打造高质量“声音教材”
(1)音频切分:通过GPT-SoVITS的Web UI工具,输入长音频绝对路径,关键参数无需调整,可将长音频自动切分为短片段(过长会影响合成质量)。本次实操将28分钟的佘诗曼访谈音频切分为183条有效片段。
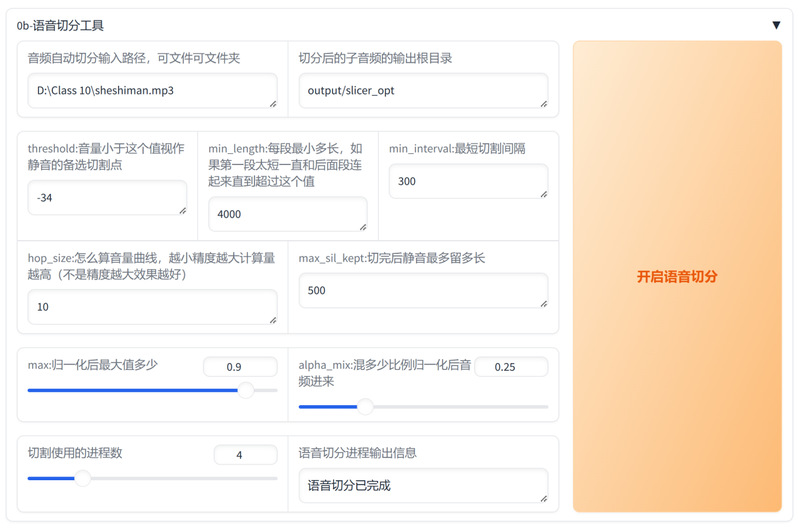
语音切分功能区
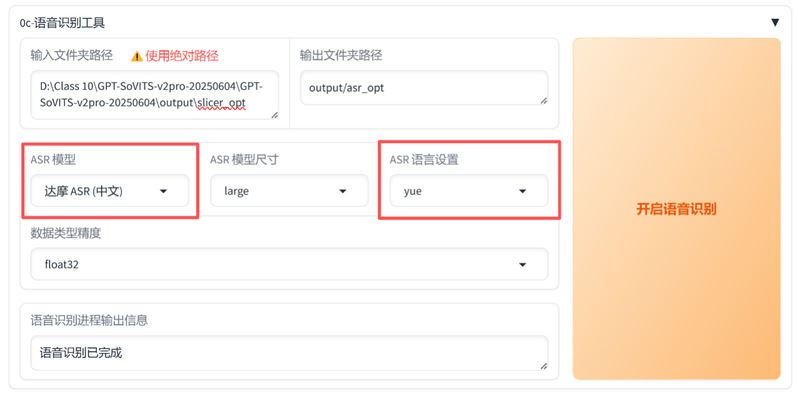
(2)语音识别:选用达摩院FunASR模型,选择粤语模式对切分音频进行转写,生成“音频-文本”对应列表。识别过程中缺失的模型会自动下载。
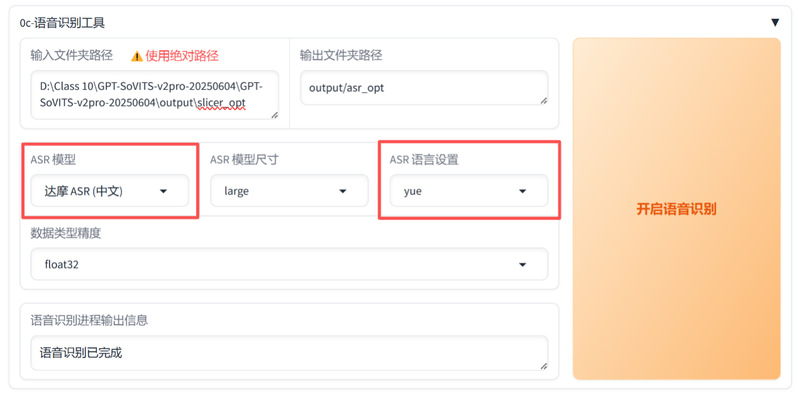
语音识别功能区
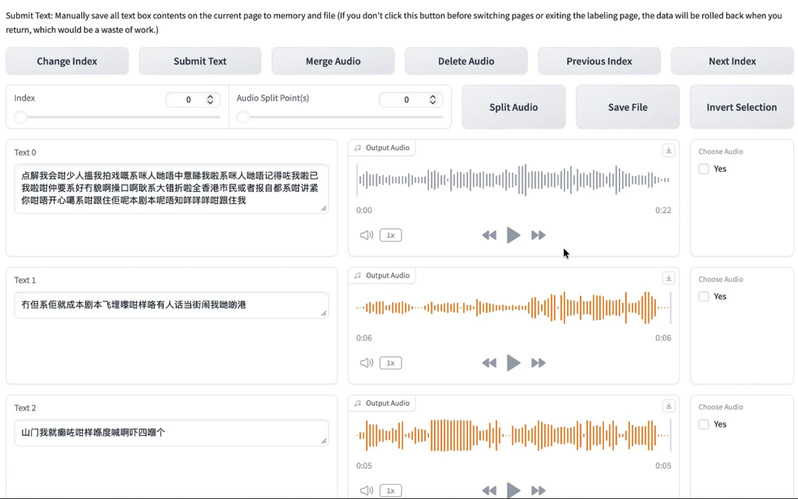
(3)人工校对:这是决定合成效果的关键步骤。完成语音识别后,点击“开启音频标注WebUI”可进行文本校对。学员需逐句对照音频与识别文本,删除非主要发音人的短片段等无关内容、修正转写错误,确保语料纯净性。
音频标注功能区
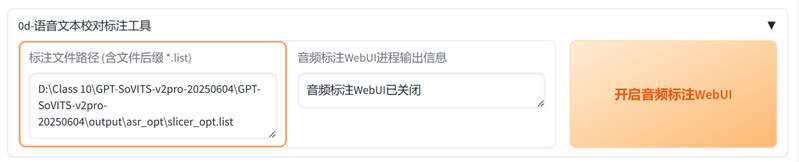
检校界面
2. 数据预处理:一键三连筑牢训练基础
完成语料校对后,需执行“文本分词、语音特征提取、语义token 生成”完成数据格式化。直接点击“开启训练集格式化一键三连”,系统会自动将处理后的数据转换为模型可识别格式,生成vocab.json词汇表,为后续微调做好准备。
训练集格式化工具界面
3. 双模型微调:循序渐进优化效果
SoVITS训练聚焦方言发音学习,让模型掌握目标人物的音色特征。GPT训练专注韵律情感复刻,还原说话人的语调起伏与节奏习惯。两项训练均支持断点续训,且默认保留验证集loss最优的3个模型权重,方便后续调用。
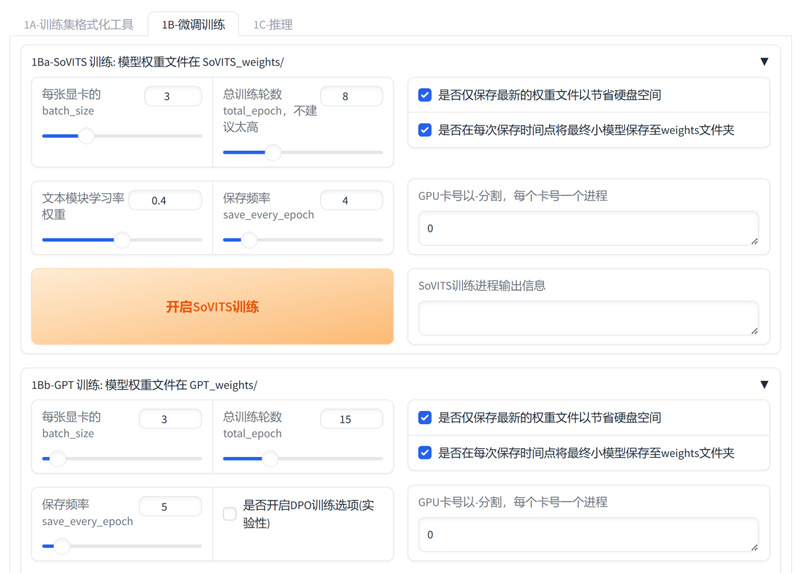
模型训练界面
11.4 推理测试:从“机械音”到“真人感”的跨越
模型训练完成后,通过推理环节验证合成效果,对比测试直观展现了微调的核心价值:
1. 底座模型vs微调模型
未经微调的底座模型合成语音平淡机械化,缺乏情感起伏,如同“冷冰冰的机器人说话”;经佘诗曼音频微调后的模型,能高度还原其粤语发音风格,今后还可以跨方言、语言复刻语调,合成普通话、英语句子时也能保持一致音色,与真人原声相似度显著提升。
2. 推理关键操作
在Web UI 中点击“1c-推理”弹出独立推理界面,需上传一段校对正确的参考音频及对应文本作为指导信号,选择训练好的模型权重,输入目标文本即可生成语音。即使未完全训练完毕,也可通过已保存的checkpoint尝试合成,提前验证效果。
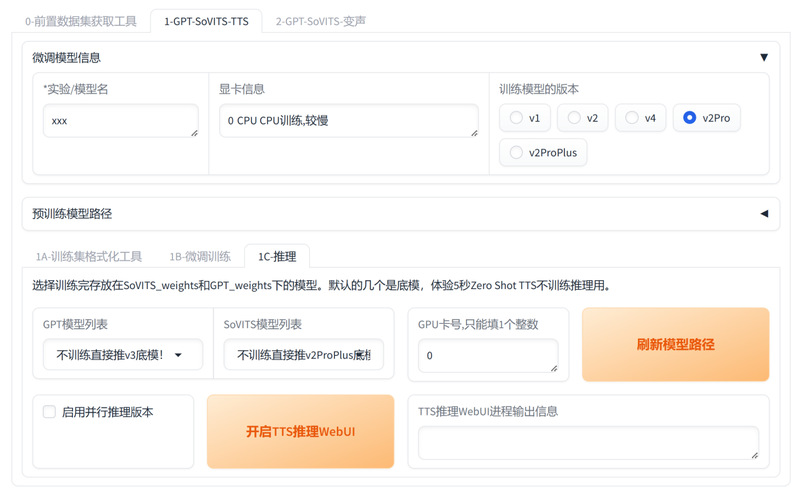
使用大语言模型开展推理界面
11.5 课程小结与课后任务
本节课通过“理论与基础知识+实操+问题拆解”的模式,让学员全面掌握了GPT-SoVITS框架的核心用法,明确了方言语音合成的三大关键要点,即高质量语料、精准标注、双模型微调。
11.6 后续课程预告
训练营最后一节课(2026年1月23日19:00)将完成方言虚拟人搭建的收尾环节,重点讲解如何将本次合成的方言语音与SadTalker平台联动,实现虚拟人口型与语音的自然同步,打造你的专属“方言虚拟人”。
主办方暨南大学方言研究中心、暨南大学-科大讯飞方言语音科技联合实验室提醒学员,学会正确使用学到的技术,用于科研、教学、文化传播,提防和甄别网上对技术的不良甚至恶意的使用。
欢迎持续关注,解锁更多“中文+AI”跨界技能!