
2026年1月23日,“中文大语言模型应用AI训练营”迎来了第十二课“项目实战七:方言虚拟人框架搭建学习(下)”。
本次课程旨在引导学员利用先进的AI工具,完成从语音合成到视觉呈现的完整闭环,最终生成具有各地方特色的方言虚拟人视频。
本次课程紧密衔接上一节课的语音合成教学,进一步深入探讨了虚拟人框架的构建与应用。邵鹏飞老师不仅演示了如何利用SadTalker平台赋予静态图片动态说话的能力,还对语音合成模型的高级应用进行了补充讲解,并对整个训练营的学习过程进行了总结与反思。
12.1 语音合成技术的进阶应用与零样本克隆
邵老师首先回顾了上一节课中关于GPT-SoVITS框架的核心知识点,并补充道,GPT-SoVITS作为一个功能全面的AI工具,不仅提供了模型下载和算力租用服务,还配备了详尽的教程,极大地降低了普通用户接触高端语音合成技术的门槛。为了让学员更直观地理解这一点,邵老师展示了GPT-SoVITS的操作指南和界面。
图1 GPT-SoVITS指南网页截图,展示文档目录和介绍
邵老师以合成知名艺人“佘诗曼”的声音为例进行了回顾。在完成了基础的模型训练后,用户其实可以让这个模型以“佘诗曼”的音色去朗读全新的、从未在训练集中出现过的文本。这种能力意味着大模型在掌握了特定的人声特征后,能够灵活地将其迁移到其他语境中,实现传统意义上的语音克隆。
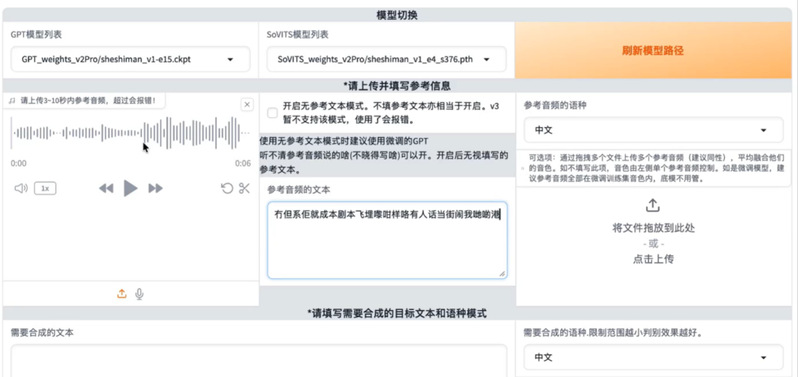
图2 GPT-SoVITS WebUI界面截图,展示模型切换和参考音频上传区域
通过这一工具,创作者不仅可以合成标准的普通话,还可以通过调整参考音频和语种设置,通过混合语种的训练方式,让AI模仿出带有特定方言韵味的声音。这为后续制作“方言虚拟人”提供了至关重要的听觉素材。学员们了解到,声音的真实感不仅来源于音色的相似,更来源于对语调、停顿以及情感的细腻把控。
12.2 构建虚拟人视觉核心——SadTalker框架解析
在解决了“声音”准备的基础上,课程的重心转移到了“视觉”层面。虚拟人技术的核心逻辑十分朴素,即通过算法将预先准备好的人声与静态的人物图像结合,使图像中的人物口型、面部表情能够随着声音的节奏发生自然的运动。为了实现这一目标,邵老师引入了本节课的主角——SadTalker框架。
邵老师强调,市面上能够实现照片说话的开源项目不仅限于SadTalker,仅用作演示选为本次课程的工具。SadTalker的工作原理是通过从音频中提取系数,进而驱动3D面部网格运动,最后渲染成视频。虽然背后的算法复杂,但对于应用层面的学员来说,关键在于掌握其部署与操作流程。
为了确保每位学员都能顺利上手,课程网站预先提供了名为Sadtalker.zip的压缩包。邵老师详细介绍了压缩包内的文件结构,其中两个文件夹尤为关键。一个是checkpoint文件夹,它包含了让静态图片“动起来”的核心权重文件;另一个是gfpgan文件夹,它内置了用于图像修复的AI模型。在生成视频的过程中,由于图像变形可能会导致画质下降,GFPGAN模型能够有效地修复人脸细节,让最终生成的虚拟人面部更加清晰自然。
12.3 环境部署实战——从依赖安装到模型配置
AI项目的本地部署往往是初学者面临的最大挑战,邵老师在课程中花费了大量篇幅演示环境搭建的具体步骤。这一过程主要依赖于命令行操作,要求学员具备一定的耐心和细致度。
首先是创建独立的虚拟环境:为使用SadTalker创建一个的Python 3.10环境。使用虚拟环境的好处在于可以将该项目的依赖库与系统中其他项目隔离开来,避免版本冲突。在激活该环境后,接下来的任务是安装运行所需的各种Python库。
课程资料中邵老师提供了一个依赖包列表(requirement_shao.txt)。学员只需在终端运行安装命令即可一键下载并安装所有必要的组件。邵老师特别提示,用户可能会遇到下载速度缓慢甚至超时的问题,因此建议在命令后添加清华大学的镜像源地址,以大幅提升下载速度。
在安装过程中,邵老师特意指出了一个潜在的“雷区”。SadTalker项目依赖于gfpgan和basicsr两个库,这两个库在某些特定版本的组合下容易发生冲突,导致程序无法运行。这是开源社区中常见的问题,需要开发者在配置时格外留意版本号的匹配。通过课程提供的预设文件,学员们可以最大程度地规避这些兼容性错误。
12.4 WebUI交互与视频生成演示
当所有环境配置工作准备就绪,邵老师在终端输入了启动命令python app_sadtalker.py。随着几行代码在屏幕上快速滚动,终端最终显示出“Running on local URL…”的提示信息,这意味着SadTalker的Web操作界面已在本地成功加载。
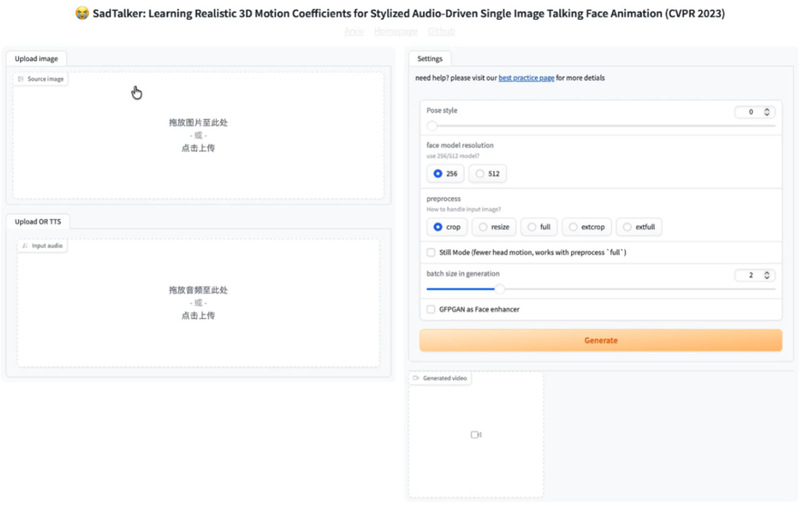
图3 SadTalker WebUI全景截图,左侧为上传区,右侧为设置区
学员们通过浏览器访问了本地地址,映入眼帘的是一个简洁直观的交互界面。邵老师演示了具体的操作流程。界面左侧分为两个主要的上传区域,上方用于上传源图片,也就是我们希望让他“开口说话”的角色照片;下方则是音频上传区,这里需要导入上一节课利用GPT-SoVITS合成好的方言音频文件。
在界面的右侧则是详细的参数设置面板。这里包含了姿态风格(Pose style)、面部模型分辨率(face model resolution)以及预处理方式(preprocess)等选项。其中,面部增强(Face enhancer)选项对应的正是前文提到的GFPGAN模型,勾选该选项可以显著提升生成视频的面部清晰度,但相应的处理时间也会增加。
邵老师选取了一张人物肖像和一段约3秒钟的合成音频进行演示。点击“Generate”按钮后,后台终端开始高速运转。虽然音频极短,但由于涉及到复杂的图像渲染和逐帧处理,生成过程仍需要一定的算力支持和等待时间。当终端日志中出现“Face renderer”字样时,表明模型正在进行最后的人脸渲染工作。
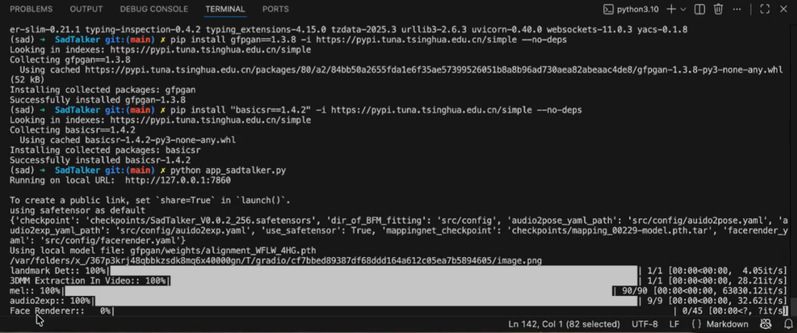
图4 后台终端中透过“Face Renderer” 查看算法核心——面部渲染进度
12.5 课程总结与未来优化方向
在课程的尾声,邵老师对整个“训练营”的教学内容进行了深度的总结。从最初的理论认知,到中期的语音合成,再到最后的虚拟人框架搭建,这套课程体系旨在帮助学员建立起对AI内容生成领域的全景式认知。
邵老师坦言,在课程设计与实施过程中,通过与学员的互动,也发现了当前教学中存在的改进空间和行业面临的挑战。
首先是算力门槛的问题。无论是GPT-SoVITS的训练还是SadTalker的推理,对显卡的性能都有较高要求。许多学员在本地设备上运行时遇到了显存不足或速度过慢的困扰。邵老师表示,未来的课程需要在这方面给予学员更多的引导,例如如何更高效地利用云端算力平台。
其次是设备与系统的碎片化带来的调试难题。学员们使用的操作系统涵盖了Windows、macOS以及Linux,且各自安装的Anaconda或Miniforge版本不一。这种环境的差异性导致在配置虚拟环境时容易出现各种意想不到的报错。这提示在未来的教学资料中,需要准备覆盖面更广的故障排查指南。
最后,邵老师提到了训练数据的重要性。AI模型的表现力在很大程度上取决于训练数据的质量与数量。在方言合成这一特定领域,高质量的、带标注的方言语音数据依然稀缺,这在一定程度上限制了最终合成效果的自然度与表现力。
随着屏幕上最后一行代码的演示结束,“训练营”画上了句号。但这并非终点,正如邵老师所言,希望学员们能够以这些项目为起点,举一反三,在AI技术日新月异的浪潮中,探索出更多属于自己的创新应用。
课程在寒假预留了一些实操练习,通过课程学习,掌握了基本实操技能的学员,将在2026年3月获得由暨南大学汉语方言研究中心、广东省岭南数字人文实验教学示范中心、暨南大学-科大讯飞方言语音科技联合实验室签发的课程学习证书。